
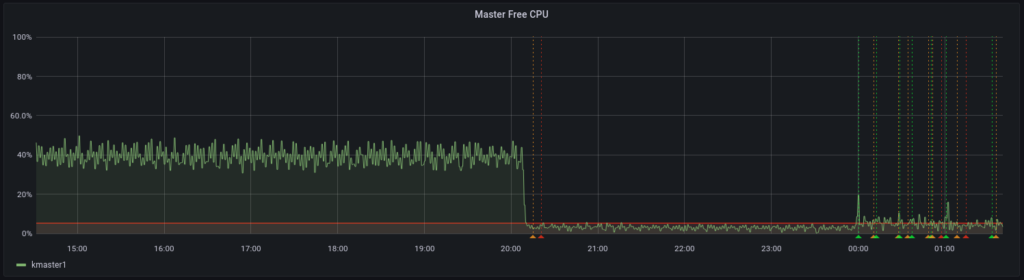
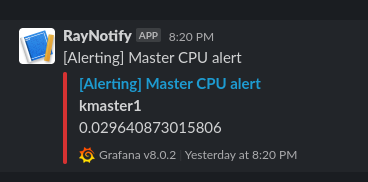
There was a Grafana alert saying that CPU usage was quite high on the master node of my garage Kubernetes cluster. I was watching a movie so I didn’t jump into this right away 🙂 I had a look at the master node today and this is how I fixed this issue.
With the good old SSH, I saw the CoreDNS process running on the master node chewing off big chunk of CPU time. From the CoreDNS pod’s logs( klogs is a handy bash function to tail a pod’s logs ):
klogs .:53 [INFO] plugin/reload: Running configuration MD5 = 33fe3fc0f84bf45fc2e8e8e9701ce653 CoreDNS-1.8.0 linux/arm64, go1.15.3, 054c9ae [ERROR] plugin/errors: 2 zipkin.istio-system. A: dial tcp 192.168.1.254:53: connect: connection refused [ERROR] plugin/errors: 2 zipkin.istio-system. A: dial tcp 192.168.1.254:53: connect: connection refused [ERROR] plugin/errors: 2 zipkin.istio-system. A: dial tcp 192.168.1.254:53: connect: connection refused [ERROR] plugin/errors: 2 zipkin.istio-system. A: dial tcp 192.168.1.254:53: connect: connection refused
From the error message an Istio plugin called zipkin was querying CoreDNS but CoreDNS couldn’t reach its upstream(192.168.1.254). I tested DNS query in the node with
dig raynix.info @192.168.1.254 ... ;; Query time: 27 msec ;; SERVER: 192.168.1.254#53(192.168.1.254) ;; WHEN: Thu Oct 28 14:45:15 AEDT 2021 ;; MSG SIZE rcvd: 72
It works in a single attempt but perhaps failed because there were too many requests at the same time. 192.168.1.254 is just a consumer grade router, it’s fair that it could not handle a lot of requests. To test this assumption, I’ll need to update CoreDNS’ configuration.
From this official document all I need to do is to change the forward directive in the configuration. I changed the default upstream to Google DNS:
# kubectl edit cm coredns -n kube-system
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
# this was forward . /etc/resolv.conf
forward . 8.8.8.8 8.8.4.4
cache 60
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
The running CoreDNS pods won’t take this change automatically, I gave them a quick restart:
kubectl rollout restart deploy coredns -n kube-system
Boom! Problem fixed. Also the calico-kube-controllers is no longer restarting, as you can see, if CPU is flat out, some pods can even fail its health check and as a result making CPU even more busy.
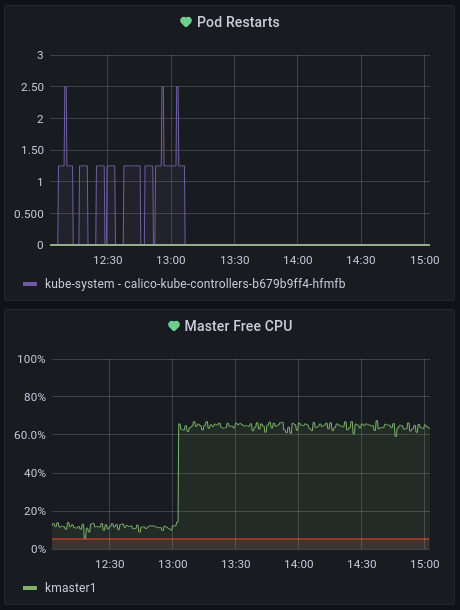
🙂